Lo reconozco: desde que descubrí Cypress, la automatización de pruebas no ha vuelto a ser lo mismo. Si bien mis orígenes en este campo se remontan a la combinación de Java, Gradle, TestNG, Selenium y Jenkins, hace ya tiempo que migré a campos más verdes con Typescript, GitHub Actions, Cypress y Cucumber. La gestión de localización de elementos de Cypress me conquistó desde el principio, por lo que no tardé en comenzar a remar hacia esta tecnología.
Si bien Cypress no proporciona soporte directo para trabajar con BDD, sí que existe una serie de paquetes que le dotan de esta versatilidad, haciendo que sea posible escribir escenarios de prueba utilizando un lenguaje natural y ejecutarlos directamente en Cypress. Esta sinergia facilita la comunicación entre los diferentes roles y mejora la visibilidad de las pruebas en todo el equipo, lo que a su vez fomenta la transparencia y el entendimiento común de los requisitos y las funcionalidades de la aplicación. En resumen: que permite que el Product Owner y otros miembros del equipo (con perfil técnico o sin él) entiendan qué funcionalidades están cubriendo las pruebas.
En este artículo vamos a aprender cómo configurar el esqueleto de un pequeño proyecto que hará uso de las siguientes tecnologías para automatizar las pruebas de una web:
- Typescript
- Cypress
- Cucumber
Para ello, utilizaremos https://the-internet.herokuapp.com como objetivo de nuestras pruebas, ya que nos ofrece una serie de funcionalidades típicas en el mundo de la automatización.
Prerrequisitos
Para llevar a cabo este proyecto, necesitaremos lo siguiente:
- Una cuenta de GitHub .
- Un IDE de desarrollo. Personalmente, recomiendo Visual Studio Code.
- NodeJS + npm instalado en nuestro equipo. Si aún no lo usas, recomiendo nvm para gestionar las versiones de NodeJS.
Creación del proyecto en GitHub
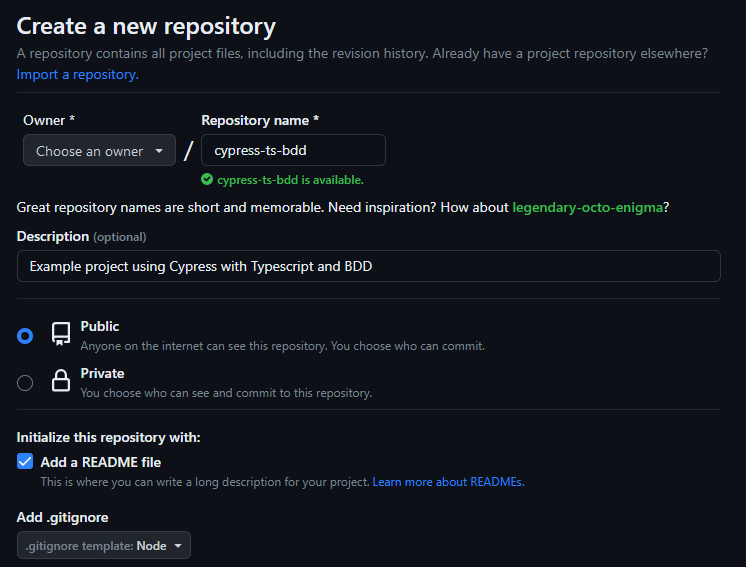
Nuestro primer paso será acceder a nuestra cuenta de GitHub y crear un nuevo repositorio. Le daremos un nombre representativo, una breve descripción, le añadiremos un README y le indicaremos "Node" como plantilla de .gitignore.
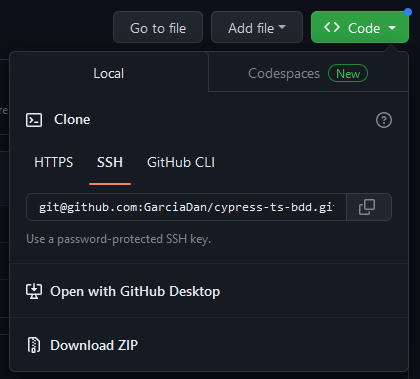
Con nuestro proyecto creado, es hora de clonarlo en nuestro IDE. Para ello, desplegaremos el menú "Code" del repositorio y copiaremos la dirección del repositorio.
Tras hacer esto, abrimos una consola nos dirigimos al directorio en el que queremos alojar localmente el repositorio y ejecutamos lo siguiente (cambiando la dirección del repositorio por el que acabamos de crear):
git clone git@github.com:GarciaDan/cypress-ts-bdd.git
Si la visibilidad del repositorio es pública, esto funcionará sin problemas. No obstante, si queremos comunicarnos con GitHub de forma efectiva y subir nuestros cambios locales al repositorio remoto, necesitaremos utilizar una clave ssh.
Para crear una clave privada, ejecutaremos lo siguiente en un terminal:
ssh-keygen -t ed25519 -C "your_email@example.com"
Esto generará una clave privada y una clave pública:
Generating public/private ed25519 key pair.
Enter file in which to save the key (/home/daniel/.ssh/id_ed25519):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/daniel/.ssh/id_ed25519
Your public key has been saved in /home/daniel/.ssh/id_ed25519.pub
The key fingerprint is:
SHA256:+Fss5a3UMmvRY+t6EjbDJC9kVCnWtP0NxsToFsZAZFY your_email@example.com
The key's randomart image is:
+--[ED25519 256]--+
| *O=Eo. |
| +ooo=o. |
| o ..o..+ |
| .+ . oo o |
| .oS=.o . .|
| ..+Oo+ |
| ooB*oo |
| =o=o |
| ..+=. |
+----[SHA256]-----+
Ahora, copiamos el contenido de la clave pública:
cat ~/.ssh/id_ed25519.pub
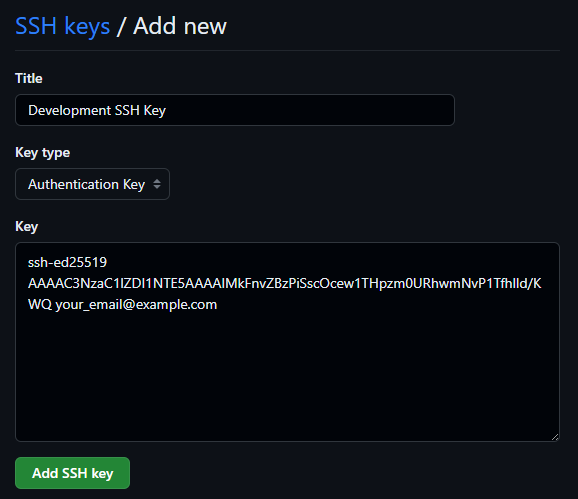
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIMkFnvZBzPiSscOcew1THpzm0URhwmNvP1Tfhlld/KWQ your_email@example.com
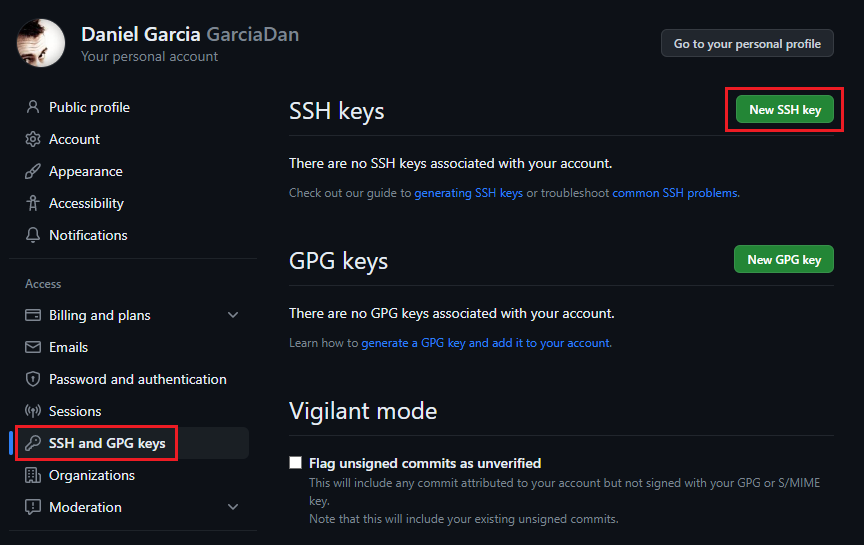
En GitHub, hacemos click en nuestro Avatar, seleccionamos "Settings" y vamos a la sección "SSH and GPG keys". Una vez allí, hacemos click en "New SSH Key"
Pegamos el contenido de la clave pública en la caja de texto y guardamos los cambios.
Con esto ya seremos capaces de utilizar nuestra clave privada para conectarnos a nuestra cuenta de GitHub. Para ello, configuraremos nuestro cliente git. Abrimos un terminal y escribimos lo siguiente (si no lo hemos hecho aún):
git config --global user.name "FIRST_NAME LAST_NAME"
git config --global user.email "your_email@example.com"
Finalmente, ejecutamos el SSH Agent y le añadimos la clave privada pasándole la ruta del fichero donde la hemos generado:
eval "$(ssh-agent -s)"
> Agent pid 59566
ssh-add ~/.ssh/id_ed25519
Con esto ya tenemos comunicación entre nuestro repositorio remoto y nuestro repositorio local.
Creación del proyecto NodeJS
En nuestro repositorio local, inicializamos un nuevo proyecto NPM.
npm init
Instalamos ahora los paquetes necesarios para nuestro proyecto:
- Cypress
- Cucumber Preprocessor
- EsBuild bundler Preprocessor
- Typescript
npm i -D cypress
npm i -D @badeball/cypress-cucumber-preprocessor
npm i -D @bahmutov/cypress-esbuild-preprocessor
npm i -D typescript
npm i -D @types/node @types/cypress-cucumber-preprocessor
Nuestro fichero package.json tendrá ahora el siguiente aspecto:
{
"name": "cypress-ts-bdd",
"version": "1.0.0",
"description": "A simple Cypress+Typescript+BDD scaffolding project",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"repository": {
"type": "git",
"url": "git+https://github.com/GarciaDan/cypress-ts-bdd.git"
},
"author": "Daniel Garcia",
"license": "ISC",
"bugs": {
"url": "https://github.com/GarciaDan/cypress-ts-bdd/issues"
},
"homepage": "https://github.com/GarciaDan/cypress-ts-bdd#readme",
"devDependencies": {
"@badeball/cypress-cucumber-preprocessor": "^17.1.1",
"@bahmutov/cypress-esbuild-preprocessor": "^2.2.0",
"@types/cypress-cucumber-preprocessor": "^4.0.1",
"@types/node": "^20.2.3",
"cypress": "^12.12.0",
"typescript": "^5.0.4"
}
}
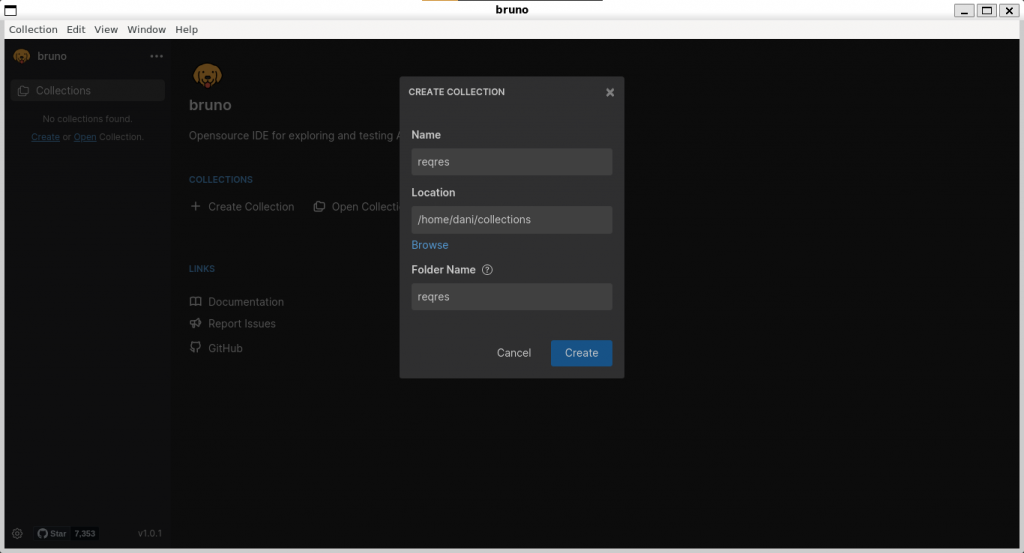
Generación de la configuración por defecto de Cypress
Cypress genera una configuración predeterminada durante la primera ejecución. Por lo tanto, abrimos la interfaz de Cypress:
npx cypress open
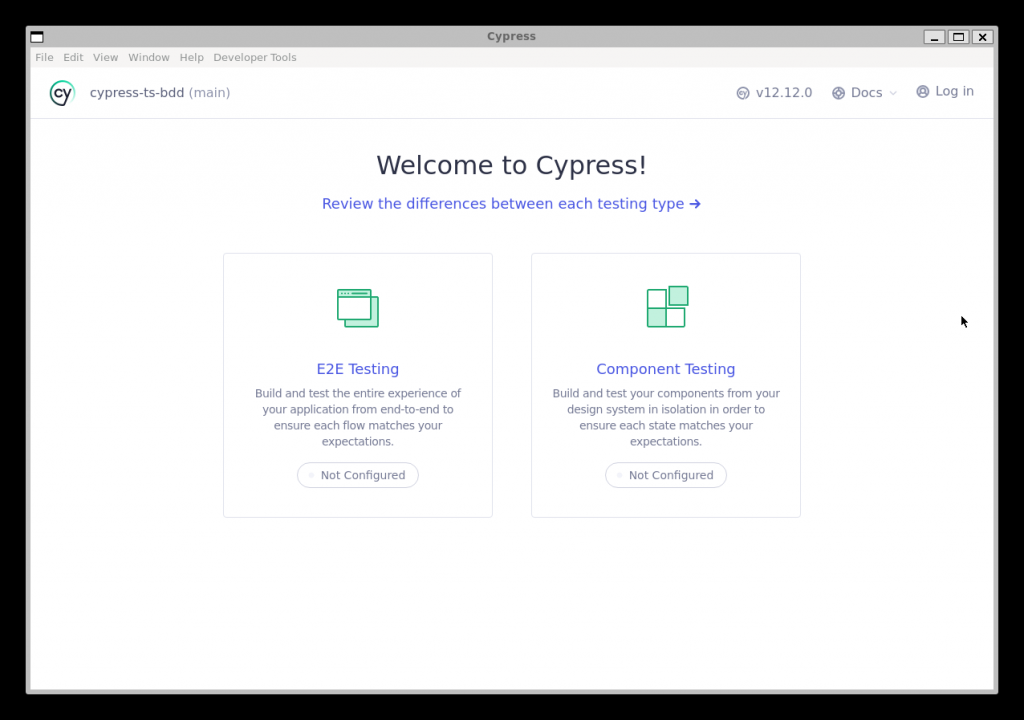
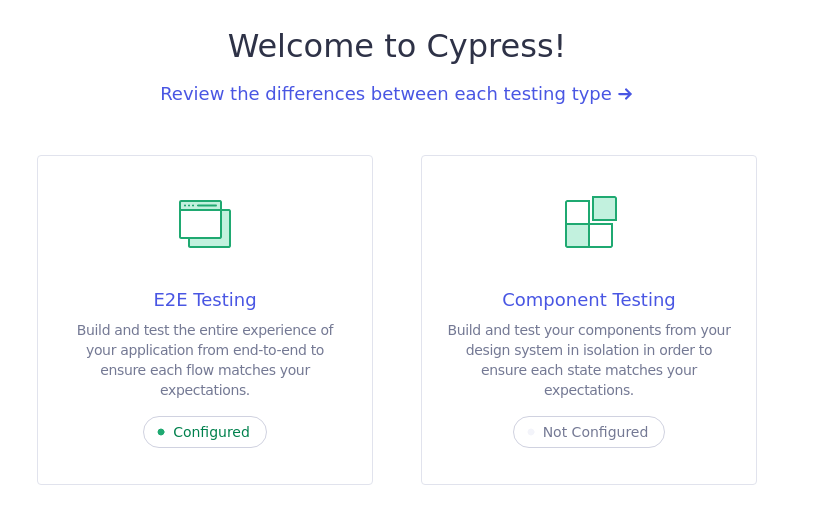
Pulsamos en "Continue >" y seleccionamos la opción "E2E Testing", que aparece en estado "Not Configured"
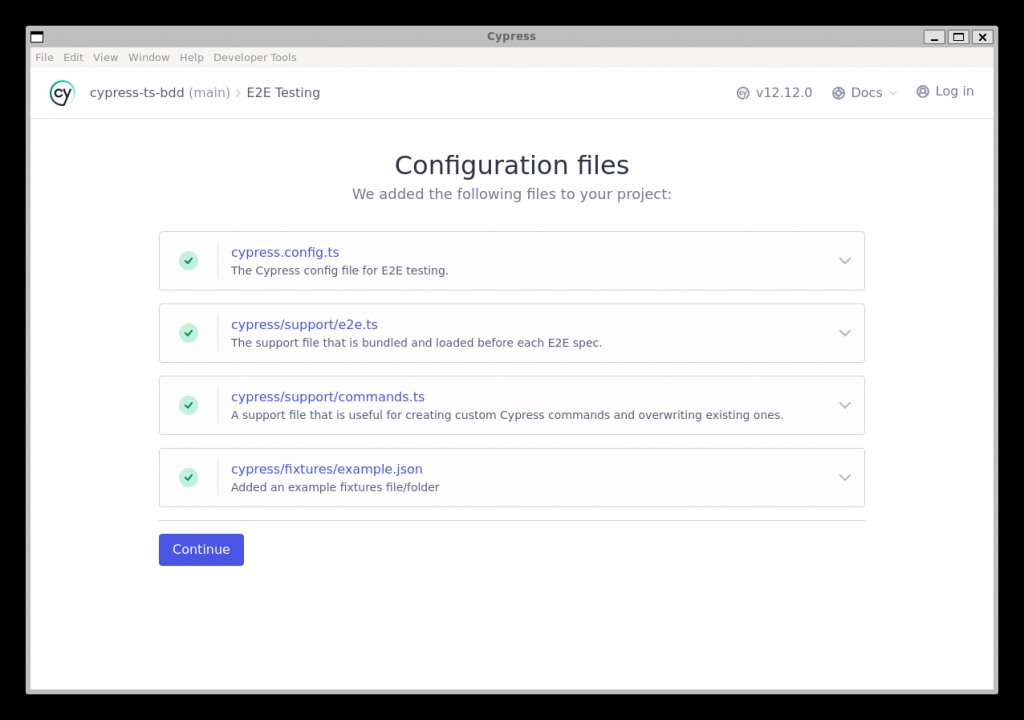
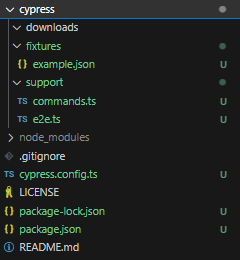
Esto debería generar los ficheros de configuración por defecto:
Ahora los ficheros de nuestro proyecto deberían de ser los siguientes:
Hecho esto, definimos el lugar donde almacenaremos la definición de los pasos (código Typescript). Añadimos lo siguiente en nuestro package.json:
"cypress-cucumber-preprocessor": {
"stepDefinitions": [
"cypress/e2e/**/*.ts"
]
}
Con lo que el fichero debería tener ahora este aspecto:
{
"name": "cypress-ts-bdd",
"version": "1.0.0",
"description": "A simple Cypress+Typescript+BDD scaffolding project",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"repository": {
"type": "git",
"url": "git+https://github.com/GarciaDan/cypress-ts-bdd.git"
},
"author": "Daniel Garcia",
"license": "ISC",
"bugs": {
"url": "https://github.com/GarciaDan/cypress-ts-bdd/issues"
},
"homepage": "https://github.com/GarciaDan/cypress-ts-bdd#readme",
"devDependencies": {
"@badeball/cypress-cucumber-preprocessor": "^17.1.1",
"@bahmutov/cypress-esbuild-preprocessor": "^2.2.0",
"@types/cypress-cucumber-preprocessor": "^4.0.1",
"@types/node": "^20.2.3",
"cypress": "^12.12.0",
"typescript": "^5.0.4"
},
"cypress-cucumber-preprocessor": {
"stepDefinitions": [
"cypress/e2e/**/*.ts"
]
}
}
Configuración de Typescript
Configuraremos ahora Typescript mediante la creación del fichero tsconfig.json en el directorio raíz del proyecto. En él incluiremos lo siguiente:
{
"compilerOptions": {
"target": "ES2021",
"lib": ["ES2021", "DOM"],
"types": ["cypress", "node"],
"moduleResolution": "node16",
"esModuleInterop": true,
"allowSyntheticDefaultImports": true
},
"include": ["**/*.ts"]
}
Con estas opciones indicaremos a typescript que transpile el código Javascript en la versión ES2021 de ECMAScript, permitiéndonos así utilizar APIs como array.include(), Object.entries(), string.trimEnd(), promise.any(), ….
- Al incluir la biblioteca "DOM" también podremos acceder a objetos del DOM como
window o document.
- Incluimos también los tipos de Cypress y de NodeJS, realizando la resolución de módulos "
node16" para dar soporte a las últimas versiones de Typescript (a partir de la versión 4.7).
- Por último, incluimos las opciones
esModuleInterop y allowSyntheticDefaultImports para evitar errores al importar ciertos módulos (como aquellos que no tienen un default export).
Configuración de Cypress
Es hora de configurar Cypress. Aunque no es obligatorio, comenzaremos creando un fichero para definir las Cypress tasks. De este modo evitaremos declararlas directamente en el fichero de configuración y su modificación será mucho más sencilla. Crearemos por ejemplo una tarea "dummy" a la que llamaremos "stdout" y que mostrará un mensaje por consola:
const tasks = {
stdout: (...data: Array<any>) => {
console.log(data)
}
};
export default tasks;
Editamos ahora el fichero de configuración cypress.config.ts, que tiene el siguiente aspecto inicial:
import { defineConfig } from "cypress";
export default defineConfig({
e2e: {
setupNodeEvents(on, config) {
// implement node event listeners here
},
},
});
Definimos aparte la función setupNodeEvents y le añadimos el preprocesador de Cucumber:
import { defineConfig } from "cypress";
import { addCucumberPreprocessorPlugin } from "@badeball/cypress-cucumber-preprocessor";
async function setupNodeEvents(
on: Cypress.PluginEvents,
config: Cypress.PluginConfigOptions
): Promise<Cypress.PluginConfigOptions> {
await addCucumberPreprocessorPlugin(on, config);
return config;
}
export default defineConfig({
e2e: {
setupNodeEvents,
},
});
Añadimos ahora el preprocesador del bundler esbuild:
import { defineConfig } from "cypress";
import { addCucumberPreprocessorPlugin } from "@badeball/cypress-cucumber-preprocessor";
import createEsbuildPlugin from "@badeball/cypress-cucumber-preprocessor/esbuild";
import createBundler from "@bahmutov/cypress-esbuild-preprocessor/src";
async function setupNodeEvents(
on: Cypress.PluginEvents,
config: Cypress.PluginConfigOptions
): Promise<Cypress.PluginConfigOptions> {
await addCucumberPreprocessorPlugin(on, config);
on(
"file:preprocessor",
createBundler({ plugins: [createEsbuildPlugin(config)] })
);
return config;
}
export default defineConfig({
e2e: {
setupNodeEvents,
},
});
Definimos las tareas. Como las hemos creado en un fichero externo, las importamos y las añadimos a la función setupNodeEvents() function:
import { defineConfig } from "cypress";
import { addCucumberPreprocessorPlugin } from "@badeball/cypress-cucumber-preprocessor";
import createEsbuildPlugin from "@badeball/cypress-cucumber-preprocessor/esbuild";
import createBundler from "@bahmutov/cypress-esbuild-preprocessor/src";
import tasks from "./cypress/support/tasks";
async function setupNodeEvents(
on: Cypress.PluginEvents,
config: Cypress.PluginConfigOptions
): Promise<Cypress.PluginConfigOptions> {
await addCucumberPreprocessorPlugin(on, config);
on(
"file:preprocessor",
createBundler({ plugins: [createEsbuildPlugin(config)] })
);
on("task", tasks);
return config;
}
export default defineConfig({
e2e: {
setupNodeEvents,
},
});
Finalmente, añadimos la siguiente configuración a defineConfig.e2e en cypress.config.ts:
specPattern: le indica a Cypress dónde buscar (y con qué patrón) las features en lenguaje Gherkin.supportFile: le indica a Cypress dónde se encuentra el fichero de soporte (e2e.ts).baseUrl: configura la URL base del proyecto.
import { defineConfig } from "cypress";
import { addCucumberPreprocessorPlugin } from "@badeball/cypress-cucumber-preprocessor";
import createEsbuildPlugin from "@badeball/cypress-cucumber-preprocessor/esbuild";
import createBundler from "@bahmutov/cypress-esbuild-preprocessor/src";
import tasks from "./cypress/support/tasks";
async function setupNodeEvents(
on: Cypress.PluginEvents,
config: Cypress.PluginConfigOptions
): Promise<Cypress.PluginConfigOptions> {
await addCucumberPreprocessorPlugin(on, config);
on(
"file:preprocessor",
createBundler({ plugins: [createEsbuildPlugin(config)] })
);
on("task", tasks);
return config;
}
export default defineConfig({
e2e: {
setupNodeEvents,
specPattern: "./cypress/e2e/**/*.{feature,features}",
supportFile: "./cypress/support/e2e.ts",
baseUrl: "https://the-internet.herokuapp.com"
},
});
Variables de entorno
En vez de definir las variables de entorno en el fichero de configuración, es aconsejable generar un fichero cypress.env.json y definirlas dentro. Por ejemplo, definiremos una variable para el nombre de usuario y otra para la contraseña:
{
"USERNAME": "tomsmith",
"PASSWORD": "SuperSecretPassword!"
}
Creación de una feature
Es el momento de crear nuestra primera prueba. Empecemos generando la siguiente estructura de carpetas:
- cypress/e2e/login/features
- cypress/e2e/login/steps
Dentro cypress/e2e/login/features, creamos el fichero login-form.feature y le añadimos la siguiente especificación:
Feature: User is able to sign in the web application
Scenario: User logs in successfully
Given the user navigates to login page
When the user provides valid credentials
Then the main page is displayed to the authenticated user
El siguiente paso es, como podremos imaginar, implementar los pasos.
Creamos el fichero login-form.cy.ts dentro de cypress/e2e/login/steps/ folder e implementar los tres pasos que acabamos de utilizar en la feature.
El primer paso hace que visitamos la URL del login:
import { Given, When, Then } from "@badeball/cypress-cucumber-preprocessor";
const LOGIN_PAGE_URL = "login";
Given("the user navigates to login page", () => {
cy.visit(LOGIN_PAGE_URL);
});
El segundo paso obtiene las variables de entorno USERNAME y PASSWORD desde cypress.env.json y los utiliza para cumplimentar el formulario de login, para justo después pulsar el botón de login:
When("the user provides valid credentials", () => {
const userName = Cypress.env("USERNAME");
const password = Cypress.env("PASSWORD");
cy.get("#username").clear().type(userName);
cy.get("#password").clear().type(password);
cy.get("button").click();
});
El último paso realiza un par de comprobaciones para asegurarnos de que la página se muestra correctamente.
Then("the main page is displayed to the authenticated user", () => {
cy.get('[class="flash success"]').should("exist").and("be.visible");
cy.get('a[href="/logout"]').should("exist").and("be.visible");
});
El fichero completo contendrá lo siguiente:
import { Given, When, Then } from "@badeball/cypress-cucumber-preprocessor";
const LOGIN_PAGE_URL = "login";
Given("the user navigates to login page", () => {
cy.visit(LOGIN_PAGE_URL);
});
When("the user provides valid credentials", () => {
const userName = Cypress.env("USERNAME");
const password = Cypress.env("PASSWORD");
cy.get("#username").clear().type(userName);
cy.get("#password").clear().type(password);
cy.get("button").click();
});
Then("the main page is displayed to the authenticated user", () => {
cy.get('[class="flash success"]').should("exist").and("be.visible");
cy.get('a[href="/logout"]').should("exist").and("be.visible");
});
Configuración de VSCode con soporte para Cucumber
Si utilizas Visual Studio Code como editor, es muy aconsejable darle soporte para Cucumber con la extensión CucumberAutoComplete. Esta extensión permite, entre otras cosas, navegar desde la definición del paso hasta su implementación, por lo que nos puede ahorrar una cantidad significativa de tiempo durante el desarrollo. Puedes obtener la extensión aquí.
Una vez instalada, edita el fichero .vscode/settings.json y añade lo siguiente:
{
"cucumberautocomplete.steps": [
"cypress/e2e/*/**/steps/*.ts"
],
"cucumberautocomplete.strictGherkinCompletion": false,
"cucumberautocomplete.smartSnippets": true
}
Ejecución de la prueba
Todo debería de estar preparado para ejecutar nuestro primer test utilizando Cypress, Typescript y Cucumber. Veamos el resultado. Abrimos un terminal y ejecutamos lo siguiente:
npx cypress open
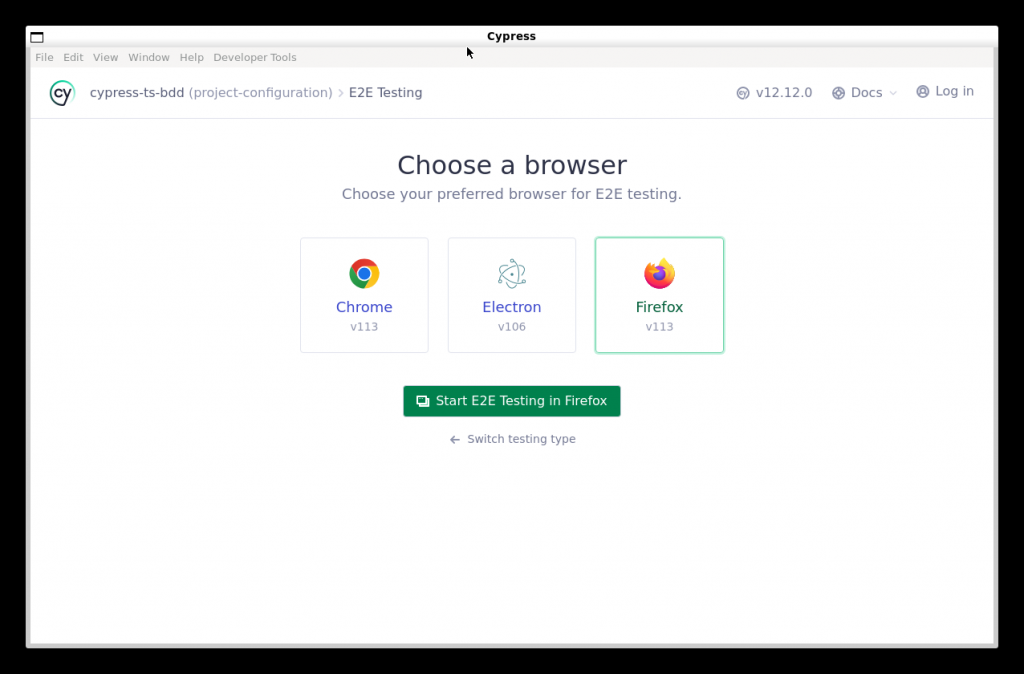
Seleccionamos la opción "E2E Testing"
Elegimos un navegador (por ejemplo, Chrome)
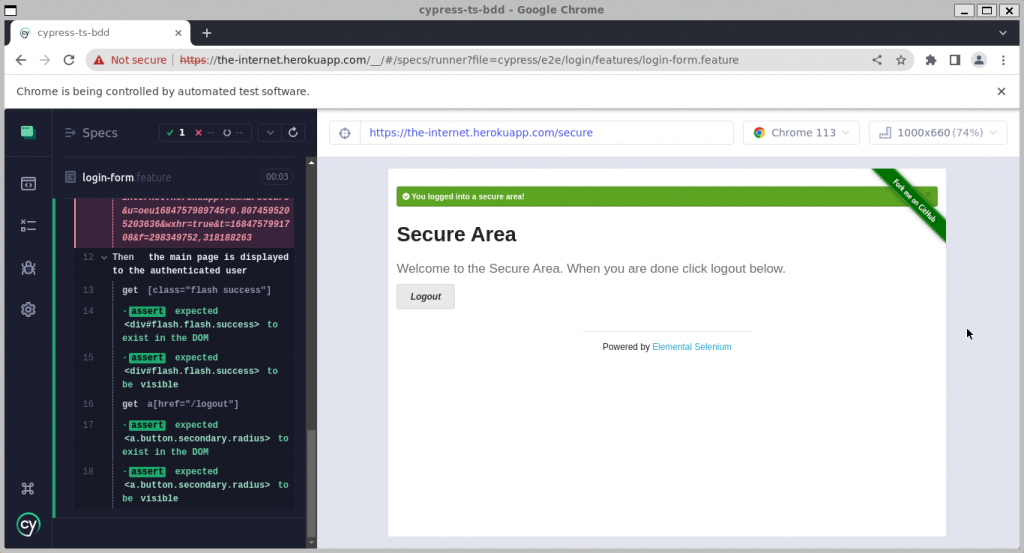
Hacemos click en login-form.feature para ejecutar el test y esperamos el resultado.
¡Hecho! Con esto, nuestro esqueleto está completo y podemos empezar a añadir más pruebas.
Puedes obtener el código relativo a esta entrada en este repositorio.